



Pour qu’une page web soit présente dans les résultats des moteurs de recherche, elle doit d’abord être indexée. Il arrive régulièrement que certaines pages ne soient pas indexées malgré le fait qu’aucune instruction d’interdiction de crawl ou d’indexation n’est envoyée aux robots des moteurs de recherche.
Plusieurs techniques SEO permettent de gérer l’indexation d’un site. Ces techniques vous permettent de stimuler l’indexation de vos pages web en incitant les bots à les crawler davantage, interdire le crawl d’une page web ou d’un dossier, transférer le potentiel ou le jus SEO d’une page web à une autre…
Comment vérifier l’indexation des pages sur Google
Pour vérifier l’état d’indexation de votre site web, il existe une technique toute simple qui vous donne en un clic le nombre de pages présent dans l’index de Google.
L’opérateur site:tondomaine.com offre un aperçu de toutes les pages présentes dans l’index de Google.
Vous pouvez également utiliser les outils d’analyse SEO disponibles sur le marché pour vérifier l’indexation de vos contenus web. Ces outils donnent un overview des performances SEO de votre site. Vos pages les plus prolifiques ainsi que d’autres indicateurs intéressants comme l’évolution des mots-clés organiques.
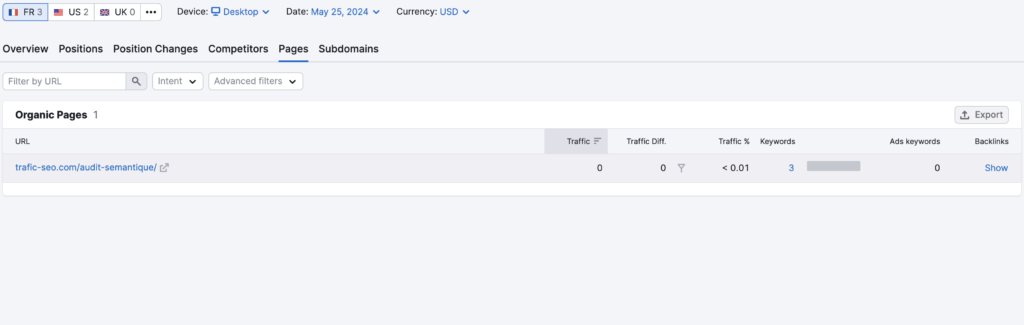
Pour cet exemple, nous prenons Semrush qui offre un aperçu des pages présentés dans l’index de Google avec la part de trafic associée.
Screaming Frog est le crawler le plus utilisé pour les audits SEO qui donne un aperçu des pages indexées. Vous aurez également un aperçu des pages non valides (3xx, 4xx, 5xx) présentes dans l’index de Google. Pour ce faire, vous devez choisir le crawler de Google dans Configuration User-Agent.

Comment soumettre une page web à l’indexation ?
Il arrive que des pages valides en 2xx ne soient pas crawlées et indexées par les bots. Même quand celles-ci sont bien ouvertes au robots sans aucune interdiction de crawl. Dans ce cas, il est possible de demander l’indexation de l’url via une fonctionnalité Google Search Console.
Dans un premier temps, il convient de vérifier si l’url est indexée ou non dans l’onglet inspection de l’url. Si l’url n’est pas indexée, vous pouvez demander à Google de l’indexer en cliquant sur “demander indexation”
Il existe également un outil sur le marché qui permet d’indexer les pages en quelques clics. Foudroyer est un outil utilisé pour inciter ou forcer Google à indexer les pages web lorsqu’elles sont en ligne. Un avantage par rapport à la fonctionnalité de la Google c’est que Foudroyer vous permet d’opérer en bulk en demandant l’indexation de plusieurs urls à la fois.
Le sitemap.xml
Le sitemap.xml est un fichier important dans l’optimisation de votre stratégie SEO. Ce fichier est accessible à la racine du site. Il joue un rôle dans l’indexation des différentes pages web du site.
Le but du sitemap est de communiquer le plan du site aux robots des moteurs de recherche. Ce fichier peut contenir toutes les ressources disponibles sur votre site. Les fichiers html, les images, les vidéos..Les bots lisent ce fichier pour mieux explorer le site web.
Le sitemap.xml facilite donc l’accès aux différentes ressources du site web.
Ce dernier facilite l’indexation de vos pages. Veillez donc à renseigner toutes les pages utiles dans le sitemap.xml pour augmenter leur chance d’indexation. Si votre site est un WordPress, vous pouvez utiliser des plugins disponibles sur le marché. Ces extensions facilitent fortement l’indexation WordPress en implémentant les recommandations techniques.
Le robots.txt
Tout comme le sitemap.xml, le robots.txt est un fichier crucial pour le SEO. Il est également disponible à la racine de votre site web.
Le robots.txt est d’ailleurs la toute première ressource visitée par les robots des moteurs de recherches quand ils arrivent sur un site web.
Cet outil est très important pour la maîtrise de l’exploration et de l’indexation d’un site web.
Il vous permet de définir quelles parties du site peuvent être explorées par les robots des moteurs de recherche et lesquelles doivent être ignorées. Cela se fait en spécifiant des directives pour chaque robot ou pour tous les robots.
La balise canonicale
La balise canonicale ou tag canonical est une balise HTML très utilisée en SEO. Le contenu de cette balise permet de spécifier aux robots des moteurs de recherche qu’une page web a un contenu similaire sur le site. La balise canonical indique donc aux bots quelle est la version originale qui doit être prise en compte.
L’un des problèmes majeurs que la balise canonicale aide à résoudre est le contenu dupliqué. En utilisant la balise canonical, vous aidez les robots des moteurs de recherche à se concentrer sur les pages pertinentes, augmentant ainsi leur capacité d’exploration.
La balise no-index
La balise “noindex” est une directive utilisée dans le référencement naturel (SEO) pour indiquer aux moteurs de recherche de ne pas indexer une page web spécifique. Cela signifie que la page en question ne sera pas incluse dans l’index des moteurs de recherche et n’apparaîtra pas dans les résultats de recherche.
Les pages en noindex seront bien crawlées mais ne seront pas présentes dans l’index des robots des moteurs de recherche.

Je suis consultant SEO & Web Analyst